-01")

Introdução
No cenário atual de comércio eletrônico e varejo online em constante expansão, um desafio comum enfrentado por empresas e consumidores é a identificação precisa de produtos em meio a vastos catálogos. Essa dificuldade surge devido à diversidade de terminologia, variações de palavras-chave e descrições inconsistentes associadas aos produtos em diferentes plataformas de compras. Para superar esse obstáculo e melhorar a eficiência na busca e comparação de itens, entra em cena uma ferramenta extremamente útil: o Product Matching. Trata-se de uma combinação de técnicas que visa identificar produtos iguais que não possuem exatamente a mesma descrição.
Aplicações
Existem diversas aplicações interessantes para essa técnica. Entre elas pode-se citar:
- Auxiliar na padronização de produtos em bases de dados;
- Comparação de produtos entre diferentes fornecedores (sites diferentes por exemplo);
- Comparação de preços para verificar se o produto é competitivo com o dos concorrentes.
Desafios
Apesar de muito útil, a aplicação dessa técnica não é tão simples. Há uma série de dificuldades envolvidas. Por exemplo:
- Inconsistência nas descrições;
- Omissão da marca;
- Formatação do nome;
- Sinônimos;
- Abreviações.
Record Linkage
Antes de elucidar o processo do Product Matching é necessário entender o conceito de Record Linkage. Esta trata-se de uma técnica que visa vincular registros de duas bases de dados distintas a partir de uma mesma entidade. Um dos principais aspectos dessa técnica é a deduplicação de dados, isto é, eliminar dados duplicados, o que acaba por criar uma base de dados unificada e de menor tamanho. Com o crescente aumento do número e da variedade de produtos, verificou-se a necessidade de relacionar produtos que fossem correspondentes entre si em diferentes base de dados, por exemplo em NFes (Notas Fiscais Eletrônicas). Para realizar tal tarefa deve-se executar as seguintes etapas:
- Pré-processamento;
- Blocking;
- Comparação;
- Classificação;
- Avaliação.
Pré-processamento
É a primeira etapa do Record Linkage, sendo composta de duas partes: limpeza e padronização. Durante a limpeza, são corrigidos valores incompletos, faltantes, incorretos ou categorizados pelo atributo errado. Durante a padronização, são descartados atributos presentes em um dataset e ausentes no outro com o intuito de deixá-los com o mesmo formato.
Blocking
Trata-se de uma tática para reduzir o tamanho do conjunto de possíveis pares correspondentes. Isso é necessário, pois, caso o conjunto fique muito grande, ele pode não caber na memória ou o processamento do mesmo nas próximas etapas se tornará muito caro computacionalmente, isto é, precisará de muitos recursos computacionais (como memória RAM) e pode demorar muito tempo. Uma estratégia de blocking é o uso de uma chave. Esta é um atributo pré-existente ou facilmente computado através dos atributos do dataset. Definida a chave, os registros só serão adicionados ao conjunto de possíveis pares correspondentes se atenderem à mesma. Um exemplo de chave seria o cnpj do fornecedor. Além disso, é possível combinar mais de uma chave, reduzindo ainda mais os possíveis pares (Exemplo: os correspondentes devem possuir descrições com as três primeiras letras iguais e o mesmo preço). Ou pode-se utilizá-las separadamente de forma a encontrar mais correspondentes (Exemplo: os correspondentes devem possuir descrições com as três primeiras letras iguais ou o mesmo preço). Há ainda a estratégia de não utilizar chaves. Para isso, utilizam-se abordagens para agrupar os registros de uma forma mais geral.
Algumas delas são:
- Blocking baseado em clusterização;
- Blocking baseado em hashing;
- Blocking por assinaturas;
- Blocking por tokens de texto;
- Blocking por atributos derivados.
Comparação
Finalizada a etapa de blocking, os registros presentes no conjunto de possíveis pares correspondentes serão submetidos a uma série de funções de comparação. Para cada par de registros é computado um feature vector. Este trata-se de uma estrutura de dados que armazena os resultados das funções de comparação. Cada elemento do feature vector é o resultado da aplicação de uma função em cima dos dados do conjunto de possíveis pares correspondentes. Alguns exemplos de funções de comparação são:
- Levenshtein Similarity;
- TF-IDF Cosine Similarity;
- Jaccard Similarity.
Após o feature vector estar completo, são gerados os conjuntos de treino e teste a partir dos dados iniciais fornecidos combinados com o feature vector, o qual é inserido no dataset de forma que cada elemento do mesmo se torna uma coluna, sendo o título de cada uma a função de similaridade utilizada.
Classificação
Na etapa de classificação, cada par de registros é predito como correspondente (match) ou não correspondente (not match) utilizando o conjunto de treino construído no passo anterior. Pode-se utilizar dois tipos de classificadores para tal:
- Classificadores supervisionados;
- Classificadores não supervisionados.
Classificação supervisionada
Utilizada para problemas em que têm-se acesso a uma categorização prévia, normalmente realizada de forma manual. Nesse caso, esses rótulos tornam-se uma coluna do conjunto de dados, que funciona tal qual um gabarito para o classificador. Um exemplo famoso que atende esse método é o dataset íris. Este consiste em um conjunto de 50 amostras das três espécies da flor Íris. Nele, para cada amostra é especificada a espécie em questão. Alguns dos principais algoritmos (conjunto de passos executados de forma a concluir uma determinada tarefa) para classificação supervisionada são:
- Regressão Logística;
- Random Forest;
- Support Vector Machine (SVM).
Classificação não supervisionada
Utilizada para problemas em que não se têm acesso a uma categorização prévia. Nela o próprio algoritmo identifica as classes dentro de um conjunto de dados, procurando padrões e similaridades nos dados a fim de criar grupos (ou clusters). Os principais algoritmos utilizados são:
- K-Means;
- Agrupamento Hierárquico;
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
Após escolher o tipo de classificação e o algoritmo adequados, é realizado o treinamento utilizando-se a parte do dataset reservada para tal. Finalizado o treino, é realizado o teste do algoritmo com o conjunto de dados de teste. Obtidos os resultados, é necessário avaliar os mesmos.
Avaliação
Para essa etapa tem-se diversos parâmetros a serem analisados para avaliar o desempenho do algoritmo. No caso de classificadores supervisionados tem-se:
- Verdadeiros Positivos ou True Positives (TP): número de registros preditos como verdadeiros (correspondentes) e que realmente o são no dataset de teste;
- Verdadeiros Negativos ou True Negatives (TN): número de registros preditos como falsos (não correspondentes) e que realmente são;
- Falsos Positivos ou False Positives (FP): número de registros preditos como correspondentes, mas que na verdade são não correspondentes;
- Falsos Negativos ou False Negative (FN): número de registros preditos como não correspondentes, mas que na verdade são correspondentes.
A partir dessas quantidades é possível obter uma série de métricas. Algumas delas são:
- Precision;
- Recall;
- F1-score.
Precision
Definida por:

Mede o número de predições verdadeiras (correspondentes) corretas.
Recall
Definida por:

Mede o número de registros preditos como correspondentes de forma correta.
F1-score
Definida por:
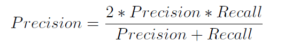
Definido como a média harmônica da precision e do recall, é frequentemente utilizada no Record Linkage para condensar a performance do classificador em um número só.
Análise e Aprimoramento do Classificador
Ao final da etapa de avaliação, define-se se o desempenho do classificador foi satisfatório. Em caso negativo, as predições são analisadas e verifica-se qual estratégia tomar para melhorar os resultados. As alterações possíveis vão desde alterar a técnica de blocking até alterar o algoritmo de classificação utilizado. Além disso, deve-se avaliar se o problema não está nos próprios dados.
Padronização de Produtos em NF-es: Uma Tarefa Complexa
Como foi citado anteriormente, a variedade e quantidade de produtos está em constante crescimento. Organizar as informações referentes aos mesmos tornou-se uma tarefa extremamente complicada. No contexto das Notas Fiscais Eletrônicas (NFes), essa deficiência na organização mostra-se muito presente. Diferentes vendedores podem vender produtos idênticos mas informar descrições diferentes na nota. Isso torna-se um problema quando deseja-se padronizar os produtos para fins de comparação de valores ou para aplicação de tributos por exemplo. Para resolver essa dificuldade o Product Matching mostra-se extremamente útil. Isso porque, ele permite a criação de uma base de dados de produtos únicos, o que torna possível a unificação de produtos com descrições diversas.
Referências
- Jeremy Foxcroft, A Comparison Framework for Product Matching Algorithms
- https://practicaldatascience.co.uk/machine-learning/how-to-create-a-product-matching-model-using-xgboost
- https://medium.com/psicodata/record-linkage-fundamentos-sus-31beb1aafd6b




-04")